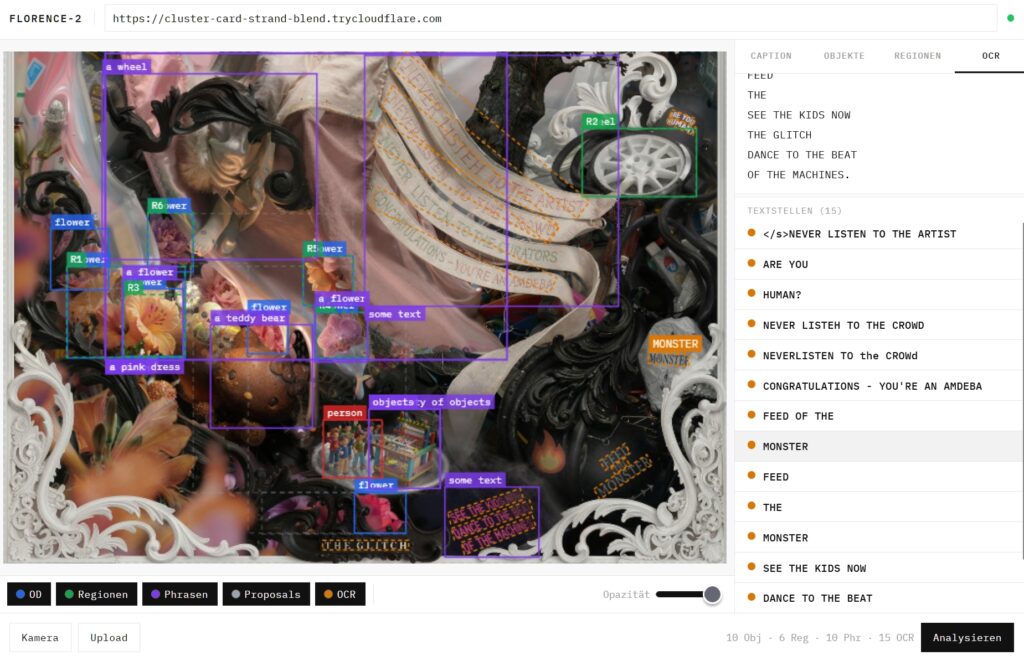
Image capturing is a key technology, when it comes to the question: What is the machine capable to detect in an image? – Not only that: When common generative models are trained, they used machine annotated data. This shows the obvious: Only the things, the machine is able to see, to contextualize – it is able to reproduce later on. With this perspective we dive into the understanding of why modern image generators come up with flat or unrelatable or very sterrotypical result. They simply do not recognize the world in all its (human perspectiv ) complexity.
The simple tool aEye is a simple demonstration of that dilemma. It uses a common image annotation ( ai based ) tool: Florence-2 to annotate any image. It comes up with a caption, that describes the content of the image, regional tags and other machine semantics. The code is available at GitHub and is based on Jupyter Notebook and simple WebUI interfaces.