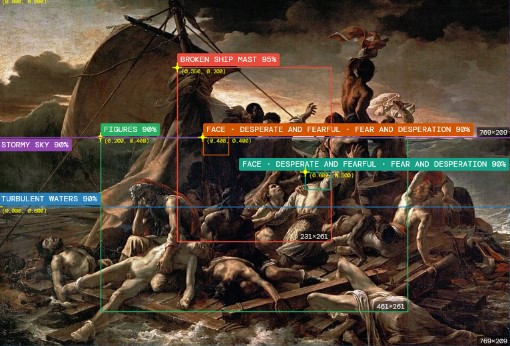
Machine vision is a crutial part when working with generative AI in a visual context. The cause is pretty simple: image generating models are essentially trained with huge amount of annotated images. Most of the annotations are done by machine vision systems like Florence or multimodal ai models. These system are pretty capable to make „sense“ of the visual input they get, but still lack a vast amount of sensitive narrativ or compositional finesse. This means: only what the machine is capable to distinguish – can be later on generated. This is a direct explanation, why most generative image models lack a certain brilliance or finesse in composition and narrative depth. In short: Only what the machine sees and conceptually „understands“ – it is capable to reproduce later on. All the inbetween is lost!
Multimodal image analysis
Most multimodal models have the capability to analyze images in a pretty elaborate way. The capability is mostly based on the LLM making sense of the basic pieces recognized by the model itself. As the descriptions and interpretations sound very elaborate, the precise understanding of object placement or composition is very rough.
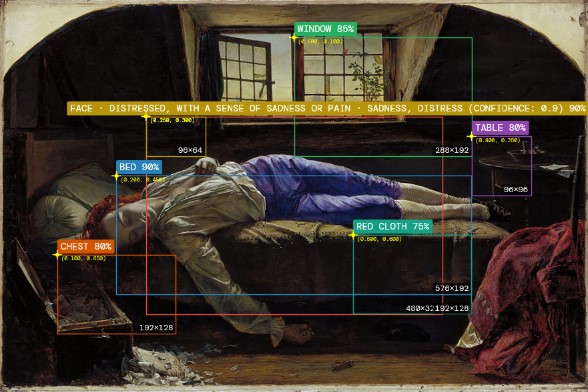
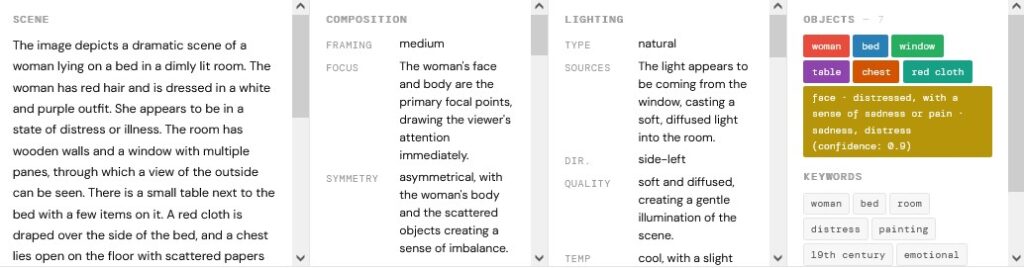
vision_Henry_Wallis_-_Chatterton_-_Google_Art_Project_20260430_1047

We can use the detailed distilled information from the recognition process as an elaborate image prompt, to reproduce a new image. This reveals some crutial offset and bias, but also the capabilities of the technology. On the first sight, the reproduction looks pretty similar, but on second sight, essential elements are missing, interpreted wrong or visually misspelled. We see a very rough study of the artefacts, biases of the technology and used models. This apprach is way off a scientifical or engnieering perspective, but gives designers and artist a pretty good impression of the capabilites and limitations of the technology.