AI image generation is powered by diffusion models, which perform a complex, iterative process of building meaningful visuals from noise. We guide this creative engine using textual prompts and specialized tools, applying fundamental principles like descriptive language, word order, and weighting to communicate our intent effectively. The entire process is anchored by a Checkpoint model, which provides the foundational understanding of visual concepts, and a seed value, which ensures reproducibility. Ultimately, wielding these tools is a practice of balance and precision, allowing us to harness the power of these sophisticated, open-source systems for creative expression.

BASICS : IMAGE DIFFUSION
It’s all about noise
Creative work with AI visual tools represents a virtuous cycle of practice, built upon the foundation of diffusion models and workflows. These systems are unique because they treat noise not as an error, but as the fundamental raw material for both learning and creation. During training, models like Stable Diffusion learn by observing how structured images are systematically dissolved into noise. In generation, this learned process is reversed, allowing artists to guide the model as it sculpts coherent visuals from that same chaotic starting point. This shared language of noise is what makes the interaction between human intention and AI generation so powerful and fluid.

Forwards & Backwards
To generate new images, we primarily use backward diffusion, a process that transforms random noise into meaningful visuals. In contrast, forward diffusion is a training tool used to teach models like Checkpoints and LoRAs by gradually adding noise to existing images.
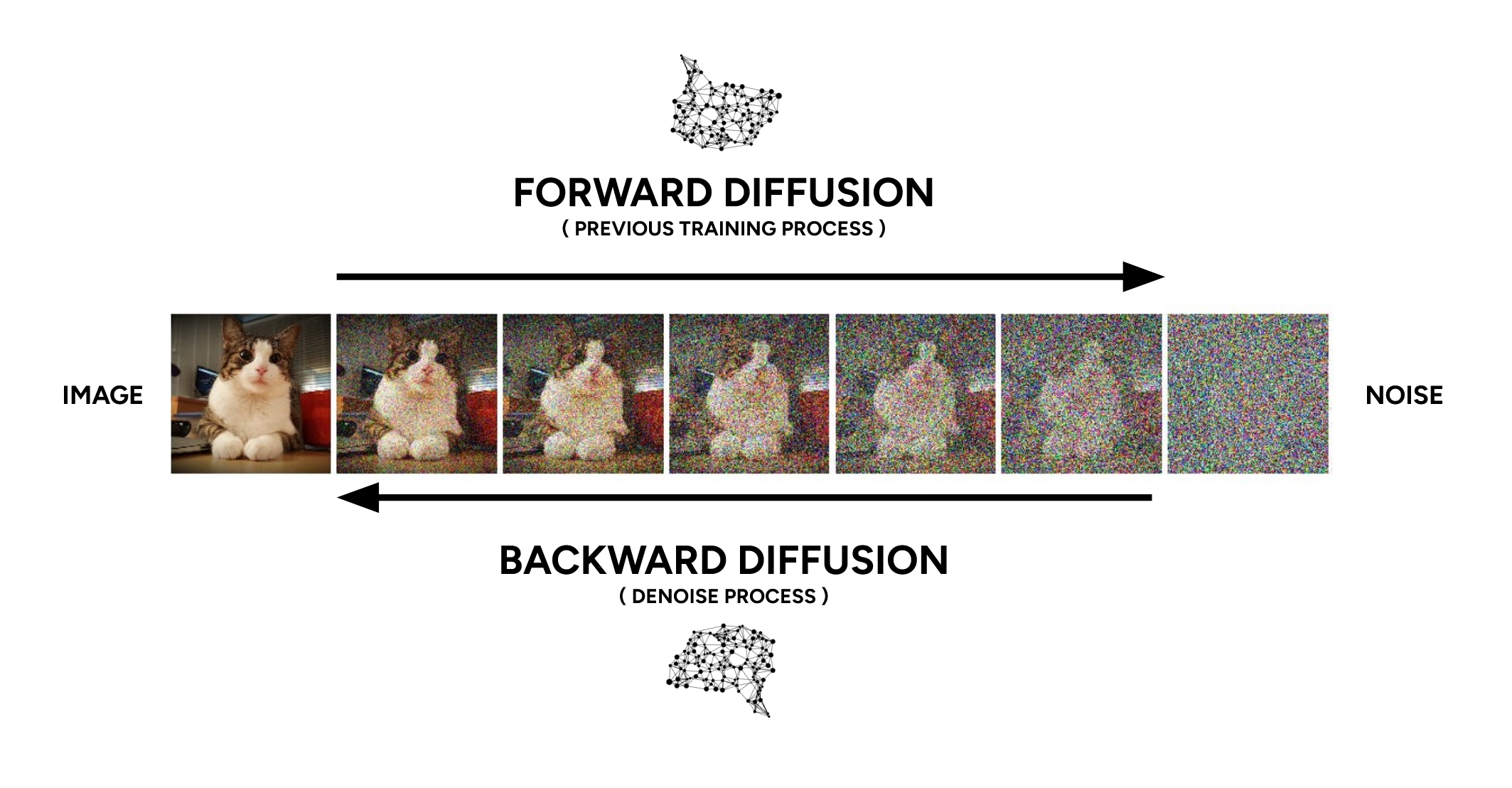
The diffusion process itself
The underlying diffusion process is inherently complex and mathematical. However, a helpful way to conceptualize it is as an intelligent feedback loop that iteratively refines noise. This system works in reverse, progressively building up visual structure and meaning from a state of pure randomness. With each step, it subtracts the „wrong“ noise and reinforces the „right“ patterns, gradually arriving at a coherent image.
CODE & DEMO: https://www.shadertoy.com/view/3XXfDn
Most common image diffusion workflow
The diffusion process is highly malleable and can be guided by various inputs. These include text prompts, image references for style or composition, and specialized tools like ControlNet for precise structural control or LoRAs for applying specific artistic styles.
It is crucial to recognize that each of these elements exerts a distinct influence on the final output. Achieving a high-quality result depends on carefully balancing these components, as they can interact and compete with one another throughout the generation process.
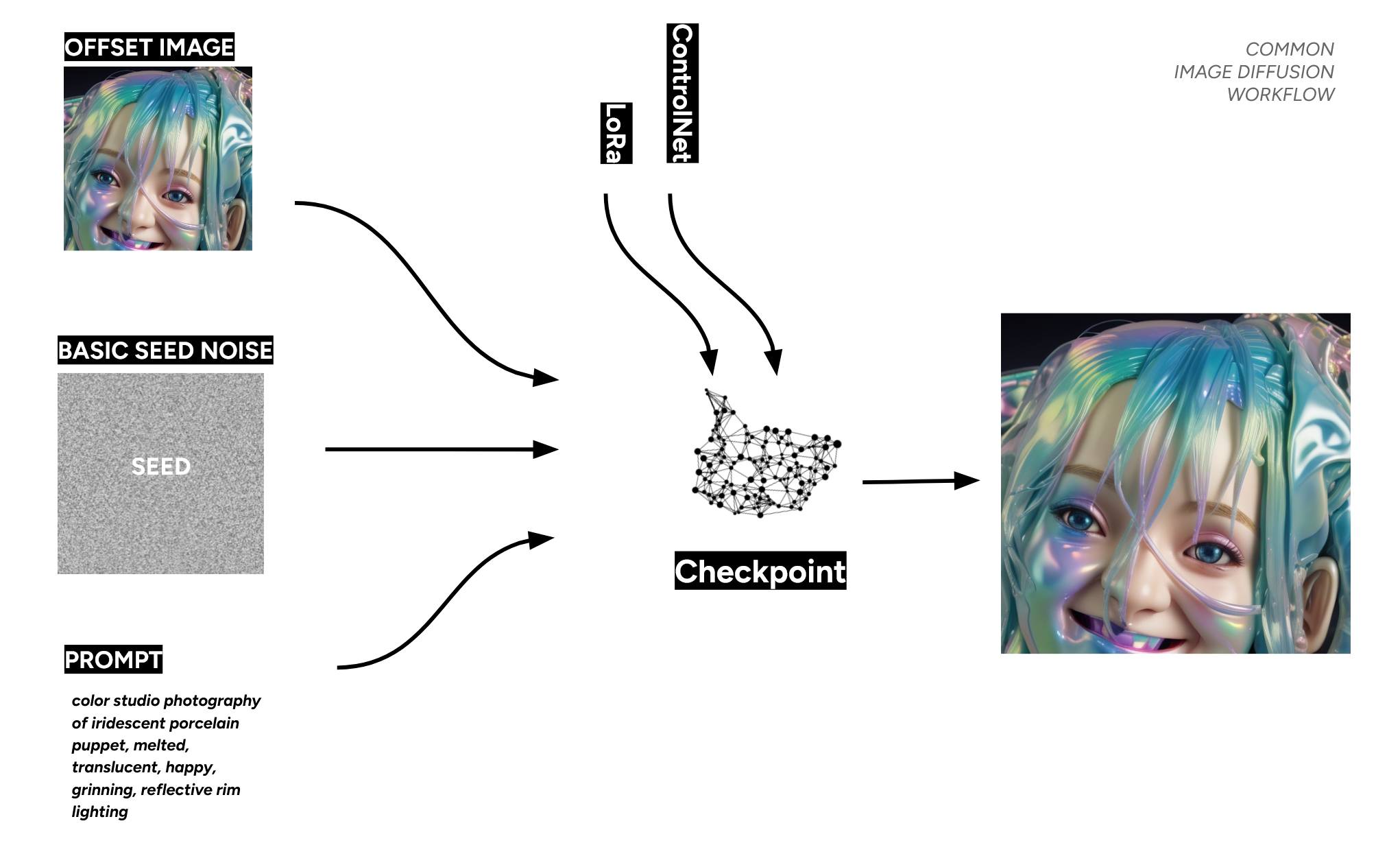
The checkpoint
The Checkpoint model is the core engine of the diffusion process. It contains the entire learned knowledge base—the understanding of language and its connection to visual concepts—necessary to translate a text prompt into an image.
Training these models requires immense computational resources and massive, annotated datasets, placing their development beyond typical consumer reach. However, thanks to the proliferation of open-source models, we are able to access and utilize this advanced technology, building upon this foundational work.

The seed
The „seed“ is a foundational element of every AI-generated image. Conceptually, it is the initial field of visual noise from which the diffusion process begins to build a picture. This means that using the exact same seed, along with the same model and prompt, will produce an identical result, allowing for perfect reproducibility.
Furthermore, the starting point does not have to be random noise; a pre-existing image can also serve as the seed. When an image is used, it acts as a powerful visual offset, heavily influencing the composition, colors, and textures of the final output.

BASICS: PROMPTING
The text prompt
Effective text prompting remains a nuanced skill without universal rules, as it is deeply dependent on the specific data and architecture of the underlying model. However, despite this variability, we can identify several fundamental principles that consistently contribute to successful outcomes across a wide range of image generation platforms.


Use representational words
It is crucial to use direct and descriptive language in your prompts. Diffusion models interpret words literally based on their training data and cannot understand complex idioms or abstract phrases like „better late than never.“ For the most reliable results, you should clearly describe the visual elements you wish to see. For instance, instead of an abstract saying, a prompt like „an illustration of a smiling clock leaning against a wall“ provides concrete, actionable concepts for the model to generate.

The order of words
The sequence of words in a prompt is critically important, as most models assign greater weight to the concepts introduced at the beginning. This means the initial words establish the primary subject and overall composition, while later terms refine the details. Consequently, the order of your prompt directly shapes the model’s interpretation and the resulting image.

Punctuation as structure
Strategic punctuation, such as commas, is a powerful tool for adding precision to your prompts. It helps the model parse and group related concepts more effectively. A good practice is to use commas to separate distinct ideas or to cluster descriptive attributes that belong to a single subject, thereby creating a clearer, more structured instruction for the model to follow.

specific weightening
As a prompt grows in length, the relative influence of each individual word on the final image diminishes. To regain control and manually emphasize or de-emphasize specific concepts, you can use user-defined weighting. This technique involves placing a word or phrase in parentheses with a numerical value, such as (a huge house:1.3) to increase its impact or (a big house:0.8) to decrease it.
It is important to note that this specific syntax for prompt weighting is not a universal standard and is primarily functional in open-source frameworks like Stable Diffusion and its derivatives.

The negative prompt
A negative prompt is a specialized parameter that allows you to specify what the model should actively exclude from the generated image, without requiring any other input. It functions as a filter, guiding the renderer away from unwanted elements, and follows the same grammatical structure as a standard positive prompt.
It is crucial to be aware that this powerful feature is predominantly available and reliable within Stable Diffusion-based architectures. In many other commercial or proprietary models, the negative prompt is either hidden from the user, implemented differently, or may not function as intended.

prompt enhancing – best practice
TODO: best practice using LLMs to enhance a basic prompt — what to take care of?
